Base58Check 编码
Base58Check 是一种可逆编码,它的基础是 Base58 编码,也就是用五十八进制来表示一个“数”。
进制和进制转换
我们可以从多个角度来理解“进制”,对于十进制,可以说成是“逢十进一”,也可以说我们一共使用 10 个不同的字符来表示数字。
一种进制系统中可以使用的数字符号的个数,称为这个进位制的基数(base)。十进制一共使用 10 个字符,十六进制一共使用 16 个字符。同一个数可以用不同的进制系统来表示,它们所代表的值是一样的,只是表示方法不同。
将 X 进制数 (an...a1a0)X 转换成十进制,只需要将它按位拆开,分别用各位的值乘以该位置对应的权值,最后求和即可。
$$ (a_n...a_1a_0)_X = \sum\limits_{i=0}^n{a_iX^i} = a_nX^n + ... + a_1X^1 + a_0X^0 $$
例如,将 (123)8 转换成十进制,结果为 (83)10。
(123)8 = 1 * 82 + 2 * 81 + 3 * 80 = 83
用“除基取余”法,可以将十进制数转换成 X 进制。例如,将 (83)10 转换成七进制,用 83 不断除以 7 直到结果为 0,得到的一系列余数就是所求结果。
$$ \begin{aligned} 83 \div 7 &= 11 \text{ ... } 6 \\ 11 \div 7 &= 1 \text{ ... } 4 \\ 1 \div 7 &= 0 \text{ ... } 1 \end{aligned} $$
所以 (83)10 转换成七进制的结果是 (146)7。
一般的,将一个数从 A 进制转换成 B 进制,我们会先将这个数从 A 进制转换成十进制,再把它从十进制转换成 B 进制。例如,将 (1324)5 转换成九进制:
(1324)5 = 1 * 53 + 3 * 52 + 2 * 51 + 4 * 50 = 214
$$ \begin{aligned} 214 \div 9 &= 23 \text{ ... }7 \\ 23 \div 9 &= 2 \text{ ... } 5 \\ 2 \div 9 &= 0 \text{ ... } 2 \end{aligned} $$
所以 (1324)5 = (214)10 = (257)9。
基于这种算法,我们可以用代码来实现任意进制数的转换。
base5 = BaseX('01234')
base7 = BaseX('0123456')
base8 = BaseX('01234567')
base9 = BaseX('012345678')
# base8('123') to dec
assert base8.to_dec('123') == 83
# dec 83 to base7
assert base7.from_dec(83) == '146'
# base5('1324') to dec
assert base5.to_dec('1324') == 214
# dec 214 to base9
assert base9.from_dec(214) == '257'
# base5('1324') to base9
assert base9.from_x('1324', base5) == '257'
assert base5.to_x('1324', base9) == '257'
# custom base10
my_base10 = BaseX(')!@#$%^&*(')
assert my_base10.to_dec('!@#$%^&*()') == 1234567890Base58
中本聪(Satoshi Nakamoto)在 BTC 中使用了自己定义的五十八进制。大小写字母加数字一共 62 个字符,剔除掉 4 个不易区分的字符,剩下的 58 个字符就是 Base58 使用的字符表。
alphanumeric 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
base58 123456789ABCDEFGH JKLMN PQRSTUVWXYZabcdefghijk mnopqrstuvwxyz注意,按此定义的五十八进制所使用的字符,并没有跟实际的数值一一对应,字符
1 实际上表示的数值是 0。
(21)58 = 1 * 581 + 0 * 580 = 58
在 BTC 中使用 Base58
编码一段二进制数据时,会先将它“看”成是十进制无符号整数,然后再做进制转换。注意到,二进制数据的前导零字节不会影响转换后整数的值,0x0012
和 0x12 都会被转成十进制数
18,所以这两段不同的二进制数据会编码出一样的结果。为了区分这种情况,编码前会先将原始二进制数据的所有前导零字节都转成字符
1。
class Base58:
b58 = BaseX('123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz')
def encode(payload: bytes) -> str:
leading_zeros = 0
for byte in payload:
if byte != 0:
break
leading_zeros += 1
encoded = ''
if payload[leading_zeros:]:
num = int.from_bytes(payload, 'big')
encoded = Base58.b58.from_dec(num)
return '1' * leading_zeros + encoded
def decode(encoded: str) -> bytes:
leading_zeros = 0
for char in encoded:
if char != '1':
break
leading_zeros += 1
num_b = b''
if encoded[leading_zeros:]:
num = Base58.b58.to_dec(encoded)
num_b = num.to_bytes((num.bit_length() + 7) // 8, 'big')
return b'\x00' * leading_zeros + num_bBase58Check
跟 Base58 相比,Base58Check 编码只多了一步校验和的计算。
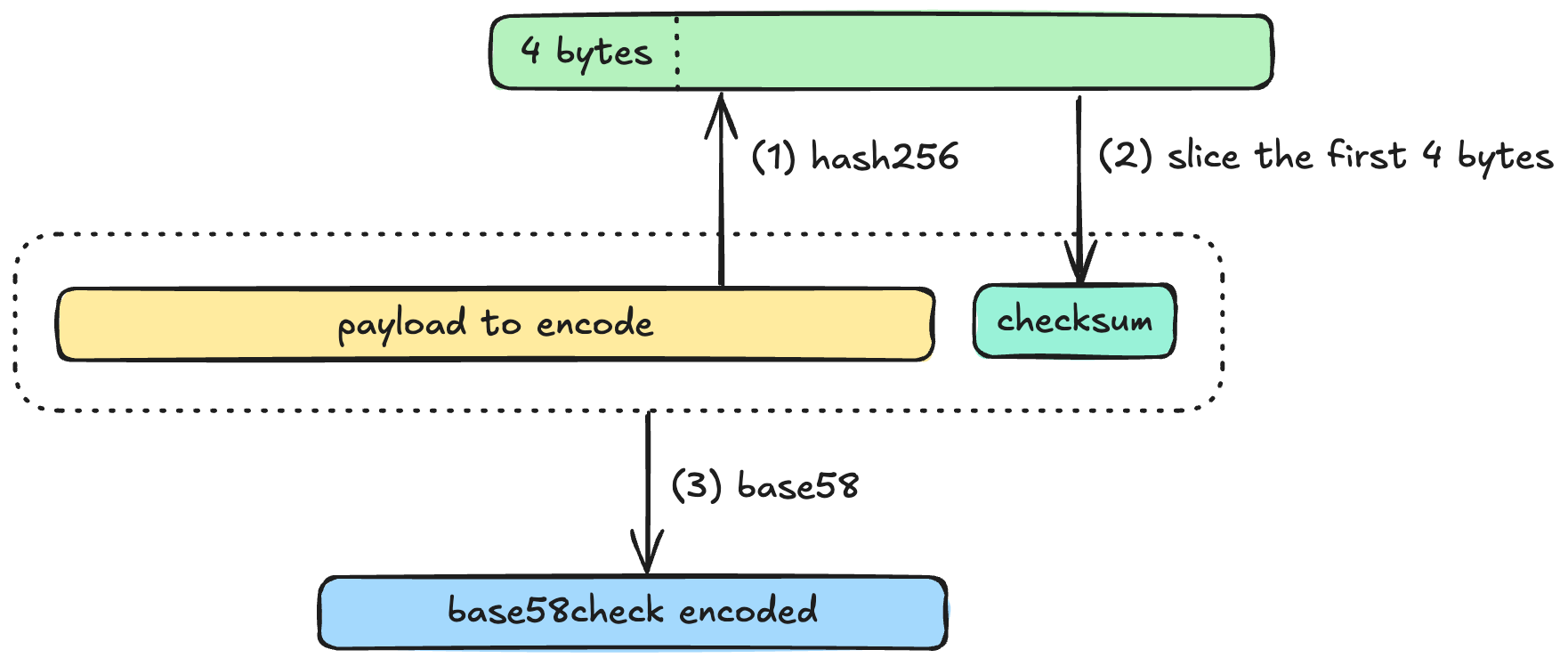
class Base58Check:
CHECKSUM_BYTES = 4
def checksum(payload: bytes) -> bytes:
return hash256(payload)[:Base58Check.CHECKSUM_BYTES]
def encode(payload: bytes) -> str:
checksum = Base58Check.checksum(payload)
return Base58.encode(payload + checksum)
def decode(encoded: str) -> bytes:
decoded = Base58.decode(encoded)
if len(decoded) < Base58Check.CHECKSUM_BYTES:
raise ValueError('invalid base58check encoded string')
payload = decoded[:-Base58Check.CHECKSUM_BYTES]
checksum = decoded[-Base58Check.CHECKSUM_BYTES:]
if Base58Check.checksum(payload) != checksum:
raise ValueError('invalid checksum')
return payload